The current version of Kubernetes (1.3) is quite packed with features to have your containerized application run smoothly in production. Some features are still a bit minimal viable product like the scaling options of the horizontal pod autoscaler (HPA). Currently you are only able to scale based on CPU and Memory consumption (custom scale metrics are in alpha).
One of our applications is a websocket server designed to have really long connected clients. While performance testing our application we found that the performance bottleneck of our application was around 25.000 active websocket connections before destabilizing and crashing. While running this load each pod did not have an elevated CPU load or memory pressure. Thus our need for scaling by websocket connection count was born. This blogpost describes our learnings while building our own custom Horizontal Pod Autoscaler.
How does the original HPA of Kubernetes work
While looking at the source code of Kubernetes (computeReplicasForCPUUtilization()) we see that the current implementation is very straightforward:
- Calculate the CPU utilization of all the pods
- Calculate the amount of pods required based on the
targetUtilization - Scale to the calculated amount of replicas
We decided we could do better. We defined the following goals for our custom HPA:
- Do not crash the application for current load (even if load exceeds available capacity
- Scale up fast, overscale if needed
- Take bootup time of new application instance in account when determining to scale
- Scale down gradually, prevent scaling down until current load is below max capacity if scaled down
Making sure our application does not crash
To prevent our application from crashing we implemented a ReadinessProbe which marks our pod as NotReady when it reaches the connection limit. This results in the Kubernetes load balancer no longer sending new traffic to this pod. Once the amount of connections to the pod start to fall below the connection limit it is marked as Ready again and starts receiving load by the Kubernetes load balancer again. This process needs to go hand in hand with the scaling of pods otherwise new request would eventually hit the load balancer with no available pods in its pool.
Fast upscaling
When scaling up we want to make sure that we can handle the increased amount of connections. Thus scaling up should happen fast, overscaling if needed. Since the application needs some time to spin up we need to predict the new load we will be receiving at the time the scale operation would be completed given that we start it now and we know the history of the websocketConnectionCount.
We initially thought about using a linear prediction based on the last n=5 websocketConnectionCount values but that led to suboptimal predictions when the amount of connections is increasing or decreasing at an exponential rate. We then started using the npm regression library to do second degree polynomial regression to find a formula which fits the evolution of our connectionCount and then solving it to gain the prediction for the next value.
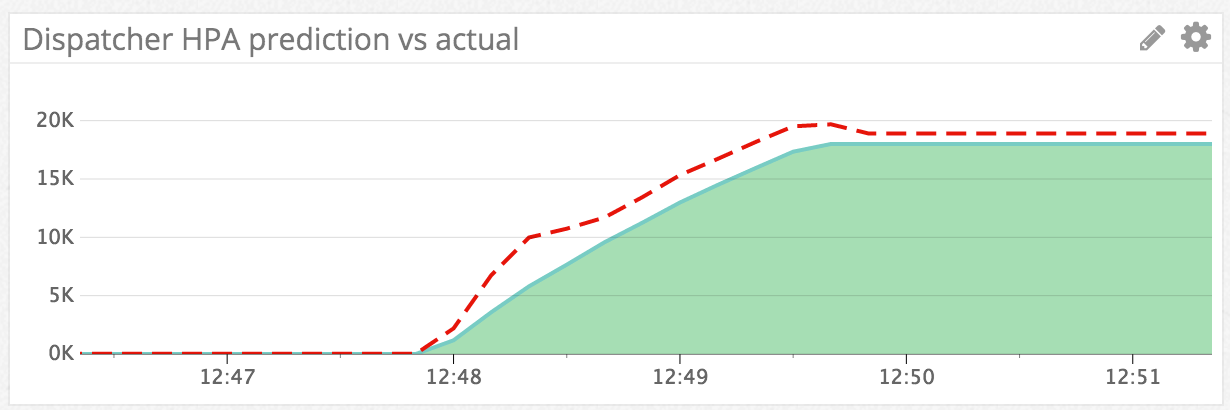
Gradual downscaling
When scaling down we do not scale based on predictions because that might result in scaling down pods which still are required for the current load. We also need to be more lenient when scaling down because our disconnected websockets will try to reconnect. So when we detect that the prediction from the polynomial regression is less than the previous websocketConnectionCount we will reduce it with 5% and use that as prediction. That way the scaling down will take pretty long and prepare us for returning connections.
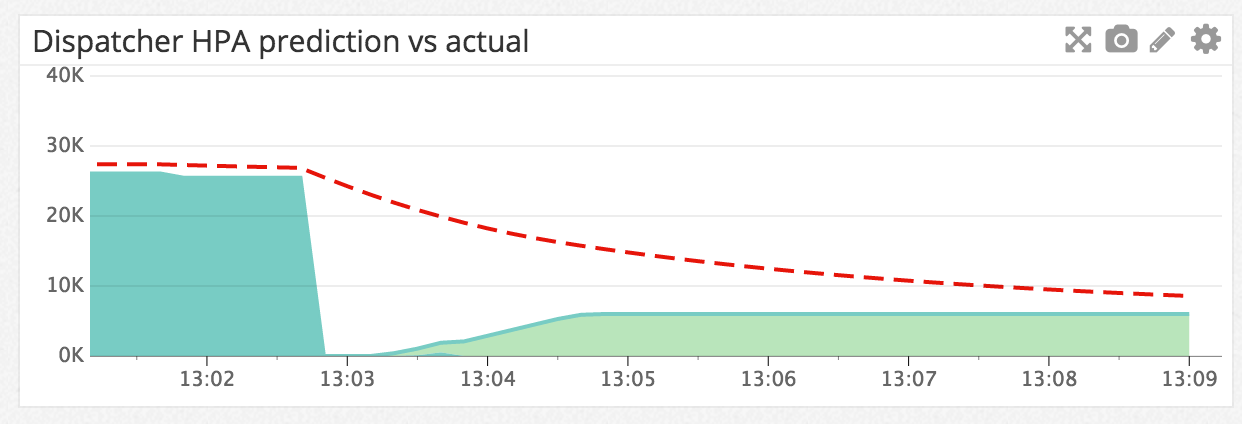
If over time those connections never return we are still downscaling but at a slow rate.
Executing Kubernetes scale operations
Because our custom HPA is running within the same Kubernetes cluster it can retrieve a service token from /var/run/secrets/kubernetes.io/serviceaccount/token to access the API running on the master. Using that token we can access the API to apply a patch http request to the replicas of the deployment containing your pods, effectively scaling your application.
Merging it all with RxJS
We used RxJS so we could use functional composition over a stream of future events. This resulted in very readable code like this:
const Rx = require('rx');
const credentials = getKubernetesCredentials();
Rx.Observable.interval(10 * 1000)
.map(i => getMetricsofPods(credentials.masterUrl, credentials.token))
.map(metrics => predictNumberOfPods(metrics, MAX_CONNECTIONS_PER_POD))
.distinctUntilChanged(prediction => prediction)
.map(prediction => scaleDeploymentInfiniteRetries(credentials.masterUrl, credentials.token, prediction))
.switch()
.subscribe(
onNext => { },
onError => {
console.log(`Uncaught error: ${onError.message} ${onError.stack}`);
process.exit(1);
});
// NOTE: getKubernetesCredentials(), getMetricsofPods(), predictNumberOfPods(), scaleDeploymentInfiniteRetries() left out for brevity
It is really elegant that we were able to use map() + switch() to keep trying to scale the deployment (+ log errors) until it succeeds or when a newer scale request is initiated.
Parting thoughts
Building our own HPA was a load of fun. Using the Kubernetes API is a great experience and is an example for how an API should be designed. At first we thought it would be a massive undertaking to develop our own HPA but in the end were really pleased with how the pieces came together. Using RxJS is a definite game changer when trying to describe the flow of your code without cluttering it with state management. Overall we are happy with the results and as far as we can tell our predictions are working quite nice with real connections.