The Philips Hue cloud infrastructure is running on Google Container Engine (Kubernetes) since 2014. We have done many Kubernetes upgrades without incidents but I want to share with you the learnings we have attained in our most recent upgrade which failed spectacularly:
Currently we are having an issue with remote connectivity (Out of Home, voice commands), and we’re working hard to resolve it ASAP. Your local connection via Wi-Fi is not affected by this. We’ll keep you posted!
— Philips Hue (@tweethue) January 3, 2019
It resulted in a production outage which took multiple hours to resolve. But to understand what went wrong and what we have learned from it we first need to discuss a bit how we normally handle Kubernetes upgrades.
New Kubernetes release, now what?
Every 12 weeks a new version of Kubernetes is released to the stable channel. It takes some time for Google to produce a GKE compatible version which is mature enough to be used in production.
Our regular approach is to wait for a bit longer after the new GKE release gets available to let the dust settle. If no bugs are raised by other Google customers we will start our upgrade by manually upgrading the master node and after this is completed we will follow suit with the upgrade of our worker nodes. This process is tested on our development clusters before being executed on the Philips Hue production environment.
On a beautiful morning in January 2019
I'm going to upgrade the production environment's nodepool today. Minor impact (elevated error rate) is to be expected due to application pods getting cycled excessively.
Famous last words. We started the upgrade by using the GKE UI and have it be done in an automated fashion by Google. It would remove one VM from the nodepool, upgrade it to Kubernetes 1.10 and return the new VM into the nodepool until all machines had been rotated. Due to the size of our cluster (~280 machines) this process takes hours.
After a few hours we observed an increase in message delivery failures to one of our partners (Amazon Alexa) which seemed to only increase. In hindsight we now know that this was caused by kube-dns somehow starting to get DNS requests from within our cluster but only having three pods effectively DDoS'ing ourselves with DNS requests.
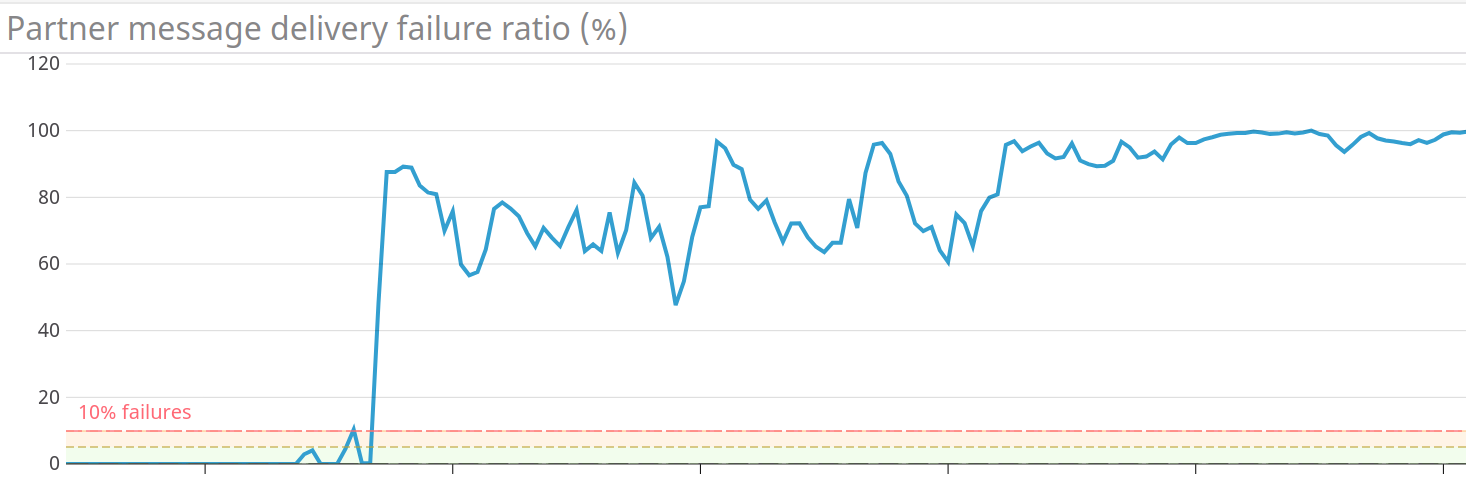
We aborted the roll-out of the new nodes and after some discussion decided to undo our partial roll-out by creating a second nodepool with 150 nodes of the original Kubernetes version and then move the workload back to these nodes, scaling further up when needed.
The wheels were set in motion. We created the nodepool with our previous kubernetes version nodes and waited for all nodes to become healthy. Only once they came online our master became unresponsive! Even though the master should only be used for the management control plane our metrics started to indicate that things just became dramatically worse, we faced a major outage. #panic
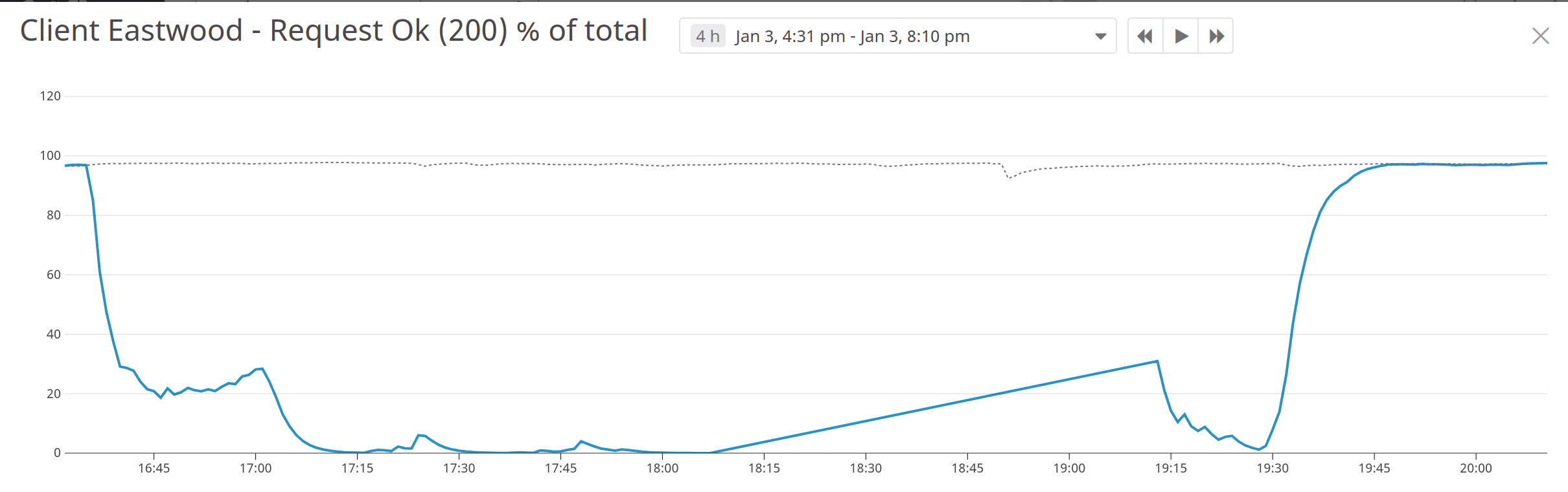
It took us multiple hours together with help from Google Support to get our GKE master node back online, deduce what caused the original error rate to go up and have our service get stable again. Unlucky achievement unlocked; get Google support engineers on our case from every geographical timezone to receive round-the-clock support.
Post Mortem
After the dust had settled we came to the conclusion that our cluster was pretty old - created somewhere in 2016 causing our DNS configuration to be incorrect. Due to the upgrade of the nodes this configuration became somehow corrected which caused DNS lookups to now hit kube-dns first - which was only running with three pods and became overloaded. Scaling kube-dns from three to 110 pods resolved a lot of that issue together with properly configuring stubDomains and upstreamNameservers.
To rollback our upgrade we created a second nodepool which (in hindsight) was of sufficient size to have our master node be automatically upgraded by Google to accommodate such amount of nodes. This made the master be unresponsive for some time and when it finally came back receive a flood of events to process and propagate to all nodes causing it to be even longer unresponsive.

What did not help in this flood of events is that one of our services contained a lot of backends (> 500 pods) - causing the size and propagation of iptables to become cumbersome. This is one of the many dimensions in which Kubernetes scalability can become an issue as discussed in "Kubernetes Scalability: a multi-dimensional analysis" (Presented at Kubecon 2018):
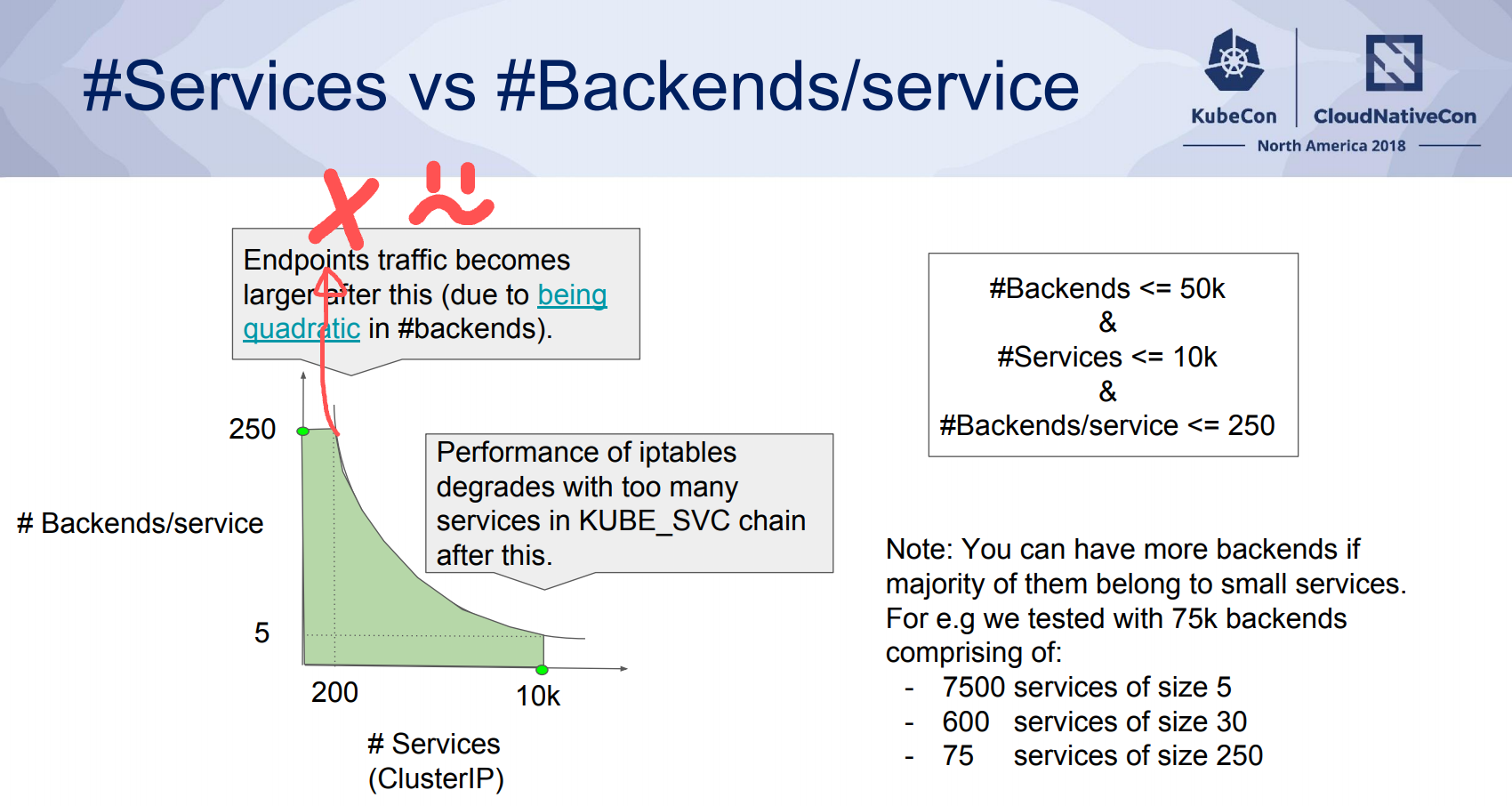
In the end we were able to resolve our outage and have our cluster become stable again. In doing so we have learned a lot about scalability and performance characteristics of our cluster. In the weeks since this outage we have been able to successfully upgrade our nodes to Kubernetes 1.10 but this again surprised us in many ways. Stay tuned for part 2 in this series!
Update: Good news – the recently reported remote connectivity issue should be resolved. We'll monitor the service closely to ensure the fix is permanent. Thank you for your patience!
— Philips Hue (@tweethue) January 3, 2019